首先说原因:软件是以英文环境开发的,开发只考虑到了西文字符集,所以字体排版的逻辑对CJK字符集(中日韩统一表意文字)的排版不友好。
西文和CJK字符集在程序中是如何处理的
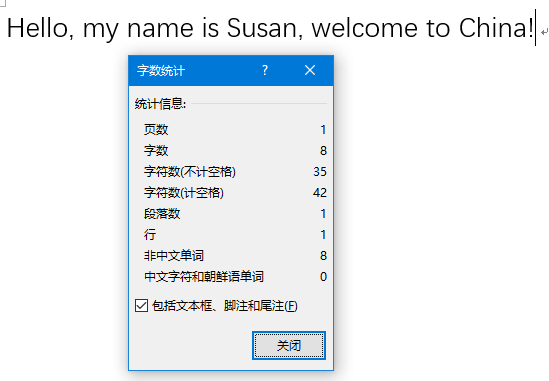
我们先来看两种字符是如何统计字数的,统计逻辑以Word的字数统计为准,首先是英文,最后字数统计是8。
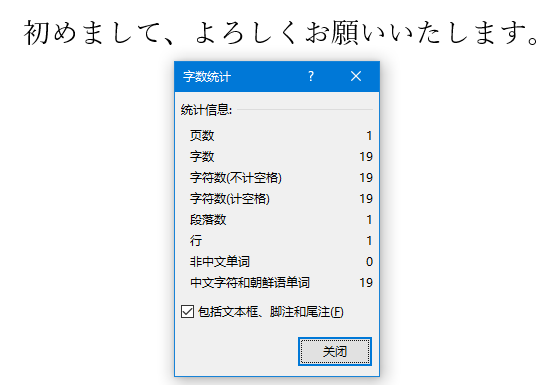
接下来是中文和日语,最后统计字数是14和19:

很直观地可以感受到,英文打了那么多字母,但最后字数还是比中日文的字数统计少。这是因为,在Word软件中,会根据文章内容的语言,自动判断应该使用什么样的逻辑去统计字数,大致的逻辑如下:
Word对于英文内容的字数统计,是按照单词数量来统计的,简单粗暴的理解,就是按照空格来划分单词(因为正确的英文文章书写,单词与单词之间是一定有空格的),你一个单词里,有一千个字母,只要中间没有空格,它就是一个单词,最后字数统计为1。
但对于CJK字符,他是按照“字符数”来统计字数的,一个文字算一个字数,一个标点符号(即使你中文文章里使用了英文标点符号),算一个字数。
中英文混排的逻辑是怎样的
说了这么多,跟中英文混排出错有什么关系呢,我们来看一张图。现在假设我们在一个没有完美支持CJK字符集排版逻辑的软件中进行文字显示,例如内容是这样的:这是中文文字前半段。FF M249SAW:这是中文文字后半段,一段超长的文字。
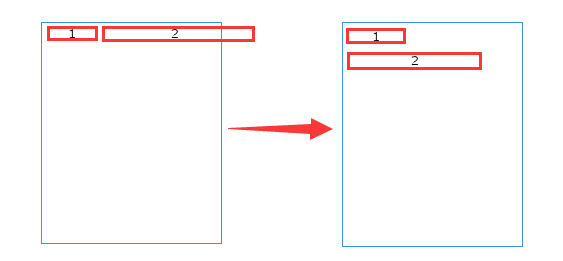
图中蓝色框线,是文字排版区域,文字显示不可以也不可能超出框。程序逻辑由于西文的文字逻辑习惯,将这段文字错误地拆分为了“这是中文文字前半段。FF”和“M249SAW:这是中文文字后半段,一段超长的文字。”,将这两段长文本,错误地理解为了两个“单词”,在图中分别标记为1和2。
程序逻辑发现,2太长了,如果将1和2排在同一行上,会导致2这个“单词”超出显示范围(如左图),于是它为了能正确显示2,将2这一段文字,进行了换行(如右图)。
所以实际在Unity中,类似莫名其妙的换行错误问题,都是这个原因导致的。

现阶段如何解决中英文混排的错误显示
目前没有特别好的解决方案,只能说,遇到一个处理一个。解决的办法也很简单,对于会提前换行的中英文混排内容,我们提前人工干预,在内容中加上换行符,如下操作:
原文:
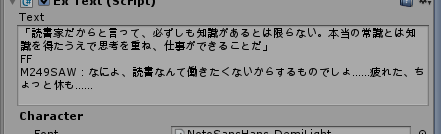
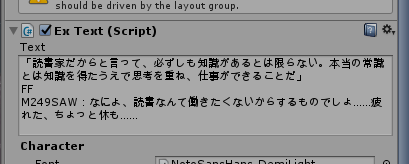
「読書家だからと言って、必ずしも知識があるとは限らない。本当の常識とは知識を得たうえで思考を重ね、仕事ができることだ」//nFF M249SAW:なによ、読書なんて働きたくないからするものでしょ……疲れた、ちょっと休も……
修改为:

「読書家だからと言って、必ずしも知識があるとは限らない。本当の常識とは知識を得たうえで思考を重ね、仕事ができることだ」//nFF M249SAW:なによ、読書なんて働きたくないからするものでしょ……//n疲れた、ちょっと休も……